
For years, folks in our industry have been developing increasingly complex models to better evaluate the effectiveness of their advertising — e.g. measuring a TV ad campaign’s impact on sales.
These kind-of-sophisticated, hard-to-understand models can take months to run, and often come too little, too late — providing results long after marketers would have needed them to optimize their next marketing campaign. But beyond just being too slow, most of these models are missing a key variable that causes them to produce inaccurate results: what the consumer would have done if they’d never seen the brand’s ad in the first place. Measurement nerds like me call this a control group. I’m sure we all remember learning that in our college stats class.
It might sound counterintuitive, but if your marketing attribution model doesn’t consider what the consumer would have done if they hadn’t been exposed to your ad, you’re simply measuring consumer behavior — not ad-driven consumer behavior, the actual impact of your advertising on the viewer.
So in order to accurately measure Convergent TV advertising efficacy, marketers need accurate, data-driven propensity modeling tools that allow them to confidently forecast consumer behavior outside the context of their campaigns. That might seem like a lot, but it’s then — and only then — that they can determine the true impact of their ads, as well as the performance gains they receive when consumers are exposed to incremental ad airings.
Data-Driven Propensity Modeling Provides an Accurate, Efficient Understanding of Baseline Consumer Behavior
The problem of trying to understand how consumer behavior changes after seeing an ad is one marketers have sought to solve for decades.
One solution available to marketers has been to set up a test group and a control group and conduct an experiment. In other words, a brand identifies a large group of people who weren’t exposed to their ads and then another group of consumers who were. Then, it can look at how those consumers engaged with the brand during the time period measured — either in terms of purchase history, online engagement, or other factors — to determine the difference between the behavior of the two groups.
However, setting up test and control groups is very costly in terms of both time and money. Don’t believe me? Just think of how much effort you’d have to go to find someone who hasn’t been exposed to a TV ad from a major brand like Coca-Cola or State Farm.
To be done correctly, marketers not only need to separate exposed consumers from non-exposed consumers, they also have to ensure that the people in their experiment are all fairly similar to one another. After all, if you unwittingly build your control group primarily out of consumers who are in-market for a new car, you might find that those shoppers were somehow more likely to purchase a product than the test group that actually saw your ads.
Another solution marketers sometimes turn to is to create a synthetic test. In this scenario, the marketer sorts consumers by various demographic qualities — e.g. age, geographic location, household income, etc — and assigns them into simulated test vs. control groups. Then, the marketer measures consumer actions in a manner similar to the controlled experiment mentioned above.
While a synthetic test avoids the high costs of the natural experiment described above, it is very difficult to do well. Crucially, a synthetic test relies on the ability to construct high-quality test and control groups and fails to incorporate the complexity of human behavior.
What marketers need instead is a data-driven propensity modeling algorithm that assesses propensity across numerous variables simultaneously and continues to correct itself based on real human behavior over time.
Let’s bring this to life with an example.
To understand why this propensity modeling is so important, imagine you are advertising winter jackets, and consider two user profiles that may exist among people who are interested in winter jackets. Person A lives in a colder locale while Person B lives in a warmer locale.
1. Suppose that for Person A (colder locale):- Probability of purchase without ad exposure: 5%
- Probability of purchase with ad exposure: 6%
- Increase in probability of purchase that is ad-driven: 1%
- Probability of purchase without ad exposure: 1%
- Probability of purchase with ad exposure: 3%
- Increase in probability of purchase that is ad-driven: 2%
In this case, if your model does account for propensity, it will yield insights that bias toward Person A because their “probability of purchase” is higher (both without and with ad exposure). However, Person B actually benefits the most from the ad exposure, because the “increase in probability to purchase that is ad-driven” is higher.
Propensity Modeling Helps Marketers Maximize Performance By Optimizing Frequency
With a robust, data-driven propensity model in hand, marketers can take the next step toward building an effective TV media plan: understanding how each additional ad exposure impacts their ad performance.
A good way of thinking about this is that an accurate propensity model tells you how likely a consumer is to engage with your brand if they never saw one of your ads. What you need to figure out next is not just how they’ll respond if they see an ad, but how they will respond if they see one ad, two ads, three ads, and so forth. This way, you can show each household the number of ad exposures that will drive the greatest performance.
For example, take a look at the graph below. In it, a brand’s target audience is sorted by zip code into three tiers, based on their propensity to engage with the advertiser.

As you can see, consumers in the High-Propensity group are most likely to engage with the brand, and households in this tier have large increases in marginal consumer engagement with each of the first three airings. In other words, advertisers can get strong performance by reaching this group with just a few airings. However, these gains peter out around the sixth airing.
By contrast, consumers in the Low-Propensity zip codes are far less likely to engage with the brand’s ads. In order to generate engagement, the advertiser must reach them a number of times. As a consequence of this, the advertiser will still get marginal returns from reaching this consumer on the fourth, fifth, and sixth airings.
Crucially, being able to map propensity to engagement enables the advertiser to determine the exact right amount of times to reach each group of consumers in a way that maximizes consumer engagement and limits wasted spend on ineffective airings.
Based on the chart above, we’re able to calculate the optimal number of airings for consumers in each of the three propensity groups. You can see them below:
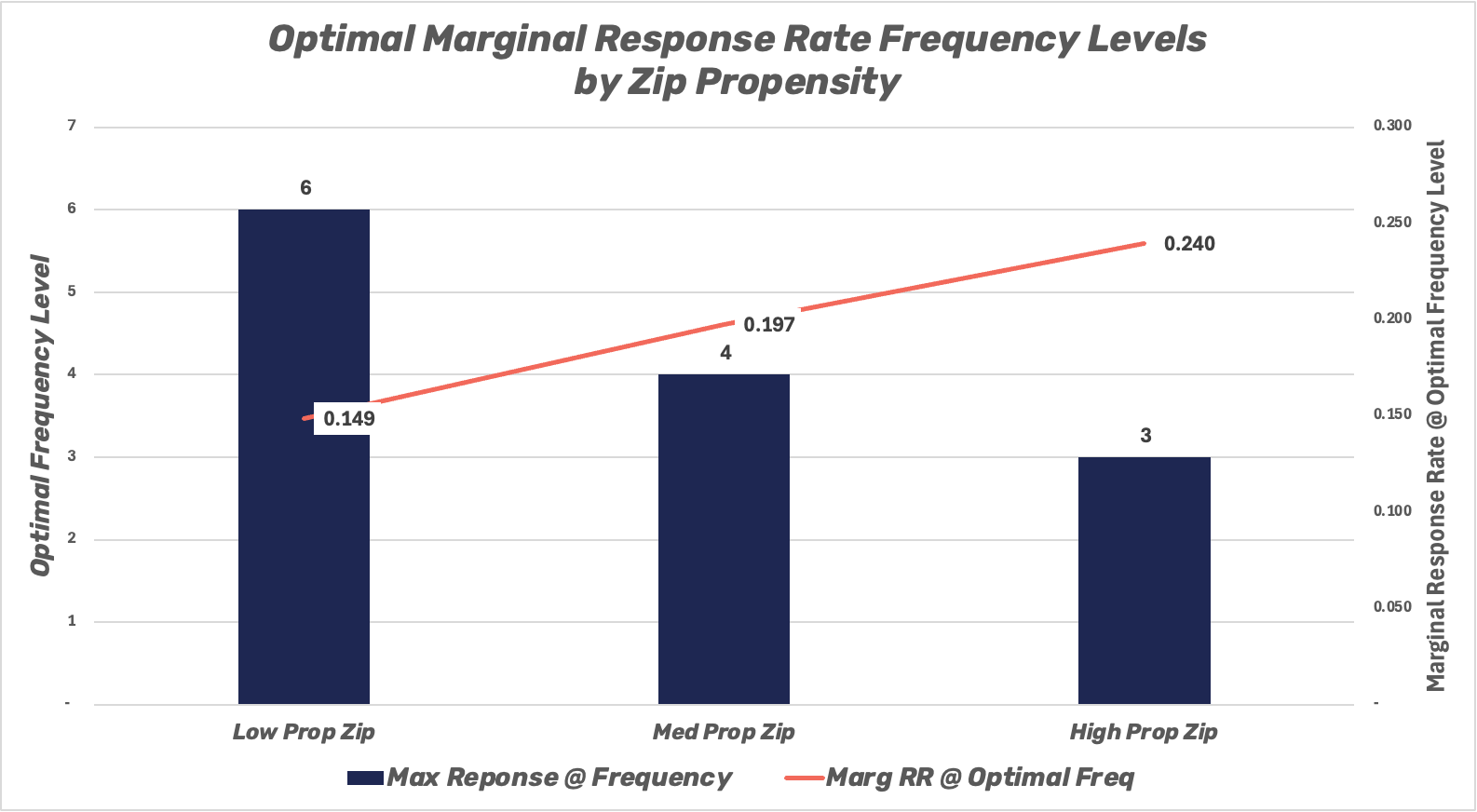
Of course, zip codes are just one way to sort consumers by propensity. You might find that your brand is best served sorting consumers by past online behavior, age, gender, household income, or other variables.
Don’t Let Bad Measurement Undermine Your Next Campaign
In order for marketers to truly understand the impact of their TV advertising, they need robust, data-driven propensity modeling that helps them separate everyday consumer behavior from ad-driven consumer actions.
Far too often, marketers spend big budgets measuring expensive campaigns, only to misunderstand the actual factors driving consumer behavior. And when you have the wrong data, you tend to make misguided decisions moving forward.
Don’t let this happen to you.
To make the most of your Convergent TV spend, modern marketers need to make sure whatever attribution model you’re using has an accurate, efficient way of measuring a crucial, but often overlooked variable: what the consumer would have done without ever seeing one of your ads.